Очень простыми и понятными словами объясняется, как работают и как можно сделать самому, рекомендательную систему. Свободный перевод потрясающей статьи How to Write Your Own Recommendation System, Part 2
Добро пожаловать. В прошлой статье была теория и примеры работы с маленькими наборами. В этой статье мы рассмотрим пример работы с реальными данными, возможности для оптимизации производительности и улучшения точности алгоритма.
Среднеквадратичное отклонение
Одним из самых важных моментов в создании рекомендательной системы является возможность сравнения результатов оценок, которые дают различные алгоритмы.
Одним из стандартных способов такой оценки является среднеквадратичное отклонение. В теории все кажется очень сложным, однако на практике это достаточно причудливое усреднение.
Для того чтобы проверить точность алгоритма нам нужны реальные данные оценок людей. После этого мы случайным образом разбиваем эти оценки(от реальных людей) на две части, обычно 80% и 20%. После этого мы используем 80% результатов для того, чтобы предсказать оценки из оставшихся 20%. А затем мы проверяем, насколько совпадают наши предсказания и реальные данные.
Вот небольшой пример для сравнения:
| Оценки пользователей | Наше предсказание | |
|---|---|---|
| 1 | 4 | 3 |
| 2 | 5 | 2 |
| 3 | 3 | 3 |
| 4 | 1 | 2 |
Вот общая формула нахождения среднеквадратичного отклонения:
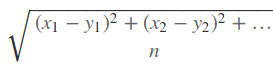
Подставляя значения получим:
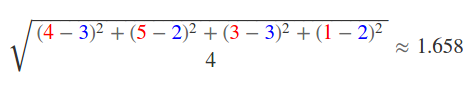
Это означает что в среднем наш результат отличается от истинного на 1.658. В общем случае, без сравнения с другими методами мы не можем сказать много это или мало, но желательно минимизировать это число.
Большие данные
Теперь нам нужны реальные данные для проверки наших алгоритмов. Прекрасные люди из GroupLens предоставляют несколько тестовых наборов данных различного объема.
Я буду использовать MovieLens 100K Dataset (100 000 оценок от 1000 пользователей по 1700 фильмам). Для того чтобы пример заработал, вам необходимо скачать этот набор. Вы можете нейти другие наборы тут.
Когда вы скачатете там будет много файлов, но нас будут интересовать только u1.base u1.test. Это данные после разбития на 80% и 20% наборы.
Некоторые замечения
Если мы будем использовать примеры из предыдущей статьи, то код будет работать очень долго. Поэтому мы применим некоторые простые улучшения:
- мы будем кешировано результаты наших вычислений
- для того чтобы уменьшить количество юзеров, по которым будет определяться оценки выбранного юзеа, мы для начала определим набор юзеров с наибольшим сходством в просмотренных фильмах, и будем работать только с этим небольшим набором
1. Случайный набор
Для начала допустим что мы случайным образом сгенерируем оценки и посмотрим на отклоненеие:
from math import sqrt
import pprint
import random
def read_file(file_path):
ratings = {}
with open(file_path) as f:
lines = f.readlines()
for line in lines:
userId, movieId, rating, _ = line.strip().split("\t")
if userId not in ratings:
ratings[userId] = {}
ratings[userId][movieId] = int(rating)
return ratings
# So our "randoms" are always the same.
random.seed(0)
test_ratings = read_file('ml-100k/u1.test')
total = 0
n = 0
print "\tItem ID\tRMSE"
for test_user in test_ratings:
for itemId in test_ratings[test_user]:
guess = random.randint(1, 5)
real = test_ratings[test_user][itemId]
diff = real - guess
total += diff * diff
n += 1.0
rmse = sqrt(total / n)
print '%d\t%s\t%.3f' % (n, itemId, rmse)Полученное отклонение равно 1.902. Это значит, что наша оценка будет отличаться от реальной в среднем на 1.902. Это интересно, но ужасно с точки зрения качества.
2. Ближайшие соседи
Как и описывалось в первой части, для оценки мы можем использовать данные ближайшего соседа, то есть того, на кого юзер наиболее похож:
class CosineDistancer:
def __init__(self):
self.cache = {}
self.cache_hits = 0
self.cache_misses = 0
def combine_users(self, user1, user2):
# Make sure we do not modify the original user data set.
user1 = copy.copy(user1)
user2 = copy.copy(user2)
# Get a unique list of the all the keys shared between the users.
all_keys = set(user1.keys()) | set(user2.keys())
# Fill in missing values so that they both have the same keys.
for key in all_keys:
if key not in user1:
user1[key] = None
if key not in user2:
user2[key] = None
# Sort by key and only get values that are shared by both users.
u1 = []
u2 = []
for key in sorted(user1.iterkeys()):
if user1[key] is not None and user2[key] is not None:
u1.append(user1[key])
u2.append(user2[key])
return u1, u2
def cosine_distance(self, user1, user2):
# Test the cache first.
cache_key = '%s:%s' % (user1, user2)
if cache_key in self.cache:
self.cache_hits += 1
return self.cache[cache_key]
else:
self.cache_misses += 1
u1, u2 = self.combine_users(user1, user2)
top = 0
user1bottom = 0
user2bottom = 0
for i in range(0, len(u1)):
if u1[i] is not None and u2[i] is not None:
top += u1[i] * u2[i]
user1bottom += u1[i] * u1[i]
user2bottom += u2[i] * u2[i]
bottom = sqrt(user1bottom) * sqrt(user2bottom)
if bottom == 0:
self.cache[cache_key] = 0
else:
self.cache[cache_key] = top / bottom
return self.cache[cache_key]
def get_users_with_item(ratings, itemId):
users = []
for userId in ratings:
if itemId in ratings[userId]:
users.append(userId)
return users
def calculate_rating_nearest(distancer, users, userId, itemId):
best_dist = 0.0
rating = None
for related_user in get_users_with_item(users, itemId):
if related_user == userId:
continue
dist = distancer.cosine_distance(users[userId], users[related_user])
if dist > best_dist:
best_dist = dist
rating = users[related_user][itemId]
if rating is None:
rating = 2.5
return rating
ratings = read_file('ml-100k/u1.base')
test_ratings = read_file('ml-100k/u1.test')
distancer = CosineDistancer()
total = 0
n = 0
print "\tItem ID\tRMSE"
for test_user in test_ratings:
for itemId in test_ratings[test_user]:
guess = calculate_rating_nearest(distancer, ratings, str(test_user),
str(itemId))
real = test_ratings[test_user][itemId]
diff = real - guess
total += diff * diff
n += 1.0
rmse = sqrt(total / n)
print '%d\t%s\t%.3f' % (n, itemId, rmse)Этот пример работает значительно дольше. Средне квадратичное отклонение получилось 1.405.
3. Средние из ближайших соседей
Вместо того чтобы пологаться на ближайшего юзера, более эффективно вычислить средние данные от определенного набора наиболее похожих пользователей. Это дает небольшое замедление по времени работы, но значительное улучшение качества:
def calculate_rating_avg(distancer, users, userId, itemId, max_n):
dist = {}
for related_user in get_users_with_item(users, itemId):
if related_user == userId:
continue
dist[related_user] = distancer.cosine_distance(users[userId], users[related_user])
sorted_dist = sorted(dist.items(), key=operator.itemgetter(1), reverse=True)
total = 0.0
n = 0
for i in range(0, max_n):
try:
total += users[sorted_dist[i][0]][itemId]
except:
break
n += 1
if n == 0:
return 2.5
return total / nТакой метода дает отклоненеие 1.047
Приз Нетфликса
Netflix prize - это открытое соревнование в котором предлагается 1 миллион долларов, любому кто сможет получить лучшие предсказания оценок чем используемый имим алгоритм. Для победы среднеквадартичное отклонение должно быть менее 0.9514.
В сентябре 2009 года комадна "BellKor's Pragmatic Chaos" смогла победить с среднеквадратичным отклонением в 0.8567.
Тут можно заметить, что с одной стороны алгоритм Netflix лучше, чем любой очевидный алгоритм, с другой стороны, для получения даже немного лучших результатов необходимо затрачивать значительно больше усилий