Очень простыми и понятными словами объясняется, как работают и как можно сделать самому, рекомендательную систему. Свободный перевод потрясающей статьи How to Write Your Own Recommendation System
Рекомендательная система - это что-то, что позволяет давать рекомендациию).Netflix - это прекрасный пример такой системы, после того как вы поставите оценки нескольким фильмам, он начинает рекомендовать новые. Вас интересовало, как он это делает? А может хотите применить это к своему сайту? Тогда давайте разбираться.
Для того чтобы примеры были понятны максимальному числу человек, я буду писать их на питоне. Для оценки фильмов я буду использовать цифры от 1 до 5, но тот же алгоритм можно применить и для любой другой системы оценки.
Маленький прототип
До того как мы займемся наборами из тысяч фильмов, мы разберемся как это устроено на небольшом примере. Я буду использовать тестовые наборы из этой статьи. HP - представляет данные по фильмам о Гарри Поттере, TW - Сумерки, SW - Звездные войны.
| HP1 | HP2 | HP3 | TW | SW1 | SW2 | |
|---|---|---|---|---|---|---|
| A | 4 | 5 | 1 | |||
| B | 5 | 5 | 4 | |||
| C | 2 | 4 | 5 | |||
| D | 3 |
A - D - это 4 пользователя, которые поставили свои оценки. Я не очень понимаю, почему пользователь D смотрел второй фильм о Поттере, не смотря первый, но раз он не поставил оценку, будем считать, что, он его не видел, и попробуем предсказать его оценку самостоятельно.
Самый простой способ найти оценку (D,HP1) - это найти человека, у которого такие же вкусы и взять его оценку. Это не совсем точно сработает для системы из 4 человек, но для тысяч пользователей результат будет прекрасным.
Как нам определить человека с такими же вкусами? Есть формула, которая называется коэффициент схожести, по которой мы можем вычислить совпадение интересов двух человек. Если схожесть равна 1, то интересы совпадают полностью. Давайте попробуем найти наиболее похожие интересы
Коэфициент схожести
Общая формула :
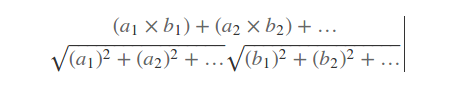 Где a и b - представляют собой оценки двух пользователей. Например вычислим схожесть пользователей A и B:
Где a и b - представляют собой оценки двух пользователей. Например вычислим схожесть пользователей A и B:
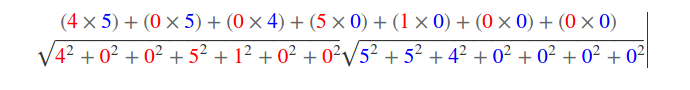
Не проставленные знания замены на нули, так что формулу можно упростить:
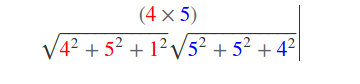
Таким способом мы получаем что схожести:
- A и D = 0.0
- B и D = 0.435
Так как пользователей у нас немного, то самый похожий пользователь на D - это - B. Теперь запишем все тоже самое в коде:
_ = 0 # A missing value.
users = {
'A': [4, _, _, 5, 1, _, _],
'B': [5, 5, 4, _, _, _, _],
'C': [_, _, _, 2, 4, 5, _],
'D': [_, 3, _, _, _, _, 3],
}
def cosine_distance(user1, user2):
top = 0
user1bottom = 0
user2bottom = 0
for i in range(0, len(user1)):
top += user1[i] * user2[i]
user1bottom += user1[i] * user1[i]
user2bottom += user2[i] * user2[i]
return top / (sqrt(user1bottom) * sqrt(user2bottom))
print cosine_distance(users['A'], users['D'])
print cosine_distance(users['B'], users['D'])Пропущенные значения были заменны на нули. Это означает, что если человек не смотрел фильм, то фильм ему сильно не понравился. Поэтому более точные результаты будут, если заменить пропущенные значения на что-то среднее: 2,5. После соответствующей замены, получим такие схожести:
- A и D = 0.915
- B и D = 0.952
Теперь мы знаем, что должны смотреть на оценки, которые поставил B. Так как у него 5, то и D фильм тоже должен понравится и получить 5.
Для того чтобы получить более точную оценку, нам нужно получить среднюю оценку от всех пользователей с учетом их коэфициента схожести. В коде это будет так:
def estimate_rating(users, userName, movie):
user_best_match = None
user_best_match_dist = 0
for user in users:
# We don't want to calculate ourself.
if user == userName:
continue
# Ignore users that haven't rated the movie.
if users[user][movie] == 0:
continue
dist = cosine_distance(users[userName], users[user])
print '%s -> %s = %.3f' % (userName, user, dist)
if dist >= user_best_match_dist:
user_best_match_dist = dist
user_best_match = user
# Return the rating of the best matched user.
return users[user_best_match][movie]
HP1, HP2, HP3, TW, SW1, SW2, SW3 = range(0, 7)
print estimate_rating(users, 'D', HP1)Продолжение
Во второй части мы рассмотрим большие наборы юзеров и фильмов. Мы поговорим о производительности и точности ваших рекомендаций, и о том как проверить точность алгоритма предсказаний.