Это третья часть рассказа об архитектуре системы рассылки. В ней я буду рассказывать про саму кодовую базу системы.
Для начала приведу UML схему того, как происходит рассылка писем:
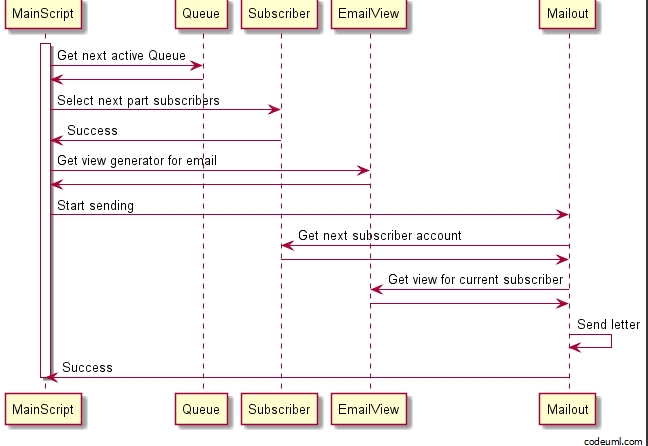
Немного поясню диаграмму:
- Существует класс
Mailout, который отвечает за отправку писем и занесение данных об этом в статистику - Сам
Mailoutне выбирает подписчиков, по которым рассылаться сообщения, или каким алгоритмом генерировать html письма. Это передается как параметрыиз скриптаMainScript(DI и принцип разделения ответственности) MainScriptуправляет и контролирует процесс рассылкиMainScriptзапускается периодически по крону или по команде из консолиMainScriptполучает из базы данных письмо, которое нужно разослать, условия рассылки (например какие аналитики подключать) и список подписчиков, которым письмо уйдет- Все полученные данные передаются в
Mailout MainScriptтакже отвечает за корректность завершения работы и сохранения данных- Если во время вызова оказывается, что можно разослать больше сообщений, чем было выбрано из базы данных, то
MainScriptповторяет все операции, пробуя отправить дополниетельные письма
Важной особенностью является возможность управлять очередностью рассылки, например приостановить рассылку или, при одновременной отправке нескольких рассылкок, пропустить одну первой. Управление было реализовано за счет 2 полей: поле status и время начала отправки time_start. В поле status могло находиться 4 значения:
- new - не рассылается, ждет окончания формирования письма
- wait - не рассылается, ждет время начала
- sending - рассылается
- sended - не рассылается, уже отослано
Код, который выбирает очередной список подписчиков, в первую очередь брал те записи, у которых статус sending. Сейчас я считаю, что такой выбор записей - это крайне неудачное решение. Такая выборка обеспечивает максимально быструю рассылку. Фактически рассылки становятся в очередь друг за другом. Это очень удобно при разработке, но, с точки зрения бизнеса, это неэффективно.
При таком способе, после каждой рассылки возникает резкий пик прихода на сайт новых посетителей и создается лишняя нагрузку на инфраструктуру. Более верным решением - максимально размазывать нагрузку. Для этого нужно при каждой выборке выбирать один список из тех, что нужно разослать случайным образом. Таким способом будет увеличено среднее время ухода рассылки и соответственно размазан пик нагрузки на инфраструктуру.
Следующее важное место - это аналитика. Для разных писем, нужно включать разную аналитику, кроме того иногда аналитику вообще нужно отключать. Фактически, вся аналитика основывается на изменении ссылок, которые есть в письме. Изменения могут быть 2 видов:
- Проксируем ссылку через сервер
- Добавляем к ссылке параметры, для отслеживания внешней системой аналитики
Для того чтобы удовлетворить требования была сделана небольшая уловка: так как письмо собирается из блоков, то подменились только те ссылки, которые были в блоках(соответственно ссылки в layout не менялись). При этом настройки, как менять ссылку, определяются самим письмом и окружением через которое рассылка рассылается.
Сам код который подменяет ссылки упрощенно выглядит следующим образом:
public function formateUrl($url, array $statisticType){
if ((count($statisticType) > 0 )) {
if (in_array('google', $statisticType)){
$type = $this->getUtmSource();
$url .= '?utm_source='.$type.date('Y_m_d').'&utm_medium=email&utm_campaign=FannyEmail';
}
if (in_array('proxy', $statisticType)){
$url = Yii::app()->params['ems']['statisticHostname'].'EmailSystem/emailApi/getLink/hashcode/[#email.code#]/lettercode/'.$this->emsBody->id.'?link='.urlencode($url);
}
}
return $url;
}
То есть, скрипт берет ссылку и последовательно проделывает строгий порядок манипуляции. Если конкретное действие не нужно, то шаг пропускается, и скрипт переходит к следующему шагу.
Данная реализация является не совсем корректной. Уловка с layout может оказаться важной и непростительной. Сейчас мне кажется, что более верным будет регулярным выражением распарсить уже сформированное письмо и заменить каждую ссылку необходимым образом. Однако в такой реализации есть одно узкое место: скорее всего заменять нужно не все ссылки (например избыточно заменять ссылки на картинки).
Следующее важное место - это токены. Токены - это значения, которые заменяются в письме на данные пользователя(например через использование токенов делается обращение в письме). Реализация токенов достаточно тривиальна: мы создаем список значений, которые будут заменены и определяем на что заменять, после этого в уже сформированном письме заменяются все значения.
Развитием токенов является письмо, содержание которого собирается на основе действий пользователя (на сайте или с другими письмами). С первого взгляда, задача кажется монструозной и относящейся к big data, но если разложить ее по шагам - то все становится достаточно просто:
- Для каждой рассылки нужен доступ к хранилищу материалов, из которых будет выбираться то, что должно быть максимально интересно пользователю. Фактически из системы рассылок нужен драйвер( или API) для доступа к хранилищу материалов
- Нужна система классификации, по которой для каждого материала в хранилище и каждого материала, который пользователь открывал, будут проставлены определенные теги. Количество тегов будет определять точность выборки и ее сложность.
- Нужна дополнить систему логирования действий пользователя: периодически проходиться по логам пользователя и определять материалы с какими тегами были интересны пользователю. Тут достаточно интересно, что можно отслеживать как меняются пристрастия у пользователя и ориентироваться и на последнии, и на общие данные. Кроме этого важным является то, что можно все делать не в реальном времени, а с запаздываением. При этом отставание практически никогда не будет критичным.
- После всех действий при рассылке отсортировать материалы по максимальному совпадению тегов и вставить материалы в письмо на отведенные места
Тут есть одно очень важное место:
- Если считается, что система знает интересы пользователей достоверно, то в письмо вставляются строго материалы по максимальному совпадению тегов
- Если считается, что знания о пользователе приближенны, то материалы с максимальным совпадением должны быть смешаны со случайной выборкой, которая позволяет уточнить данные о пользователе
И последней интересный момент - это проведение A\b тестирование. A\b тестирование заключается в том, что подписчикам рассылаются письма отличающиеся в каком, то одном свойстве (например одной категории письмо отправляется в 5 утра, а второй в 8 вечера) и сравниваются результаты. На мой взгляд проводить подобное тестирование можно если подписчиков более 5000, меньше результаты становятся неотличимы от погрешностей.
Важным и критичным для верного тестирования является случайность выборки подписчиков, которые получат конкретный вариант письма. ( Если вы разделите список подписчиков на 2 части и первой всегда будете слать письмо утром, а второй части списка - вечером, то вы только проверите как реагирует конкретная часть списка на конкретное время).
В A\b тестировании наиболее интересным была реализация: схема рассылки осталась прежней, но была немного расширена. Удобно считать, что есть 2 письма, которые должны уйти по одному списку подписчиков. Для того чтобы определить какое из писем должен получить каждый подписчик достаточно запустить генератор случайных чисел и для каждого подписчика проверить какое число выдаст генератор: если число четное, то отправить первое письмо, нечетное - второе. Гарантом того что подписчик получит только одно письмо будет одинаковый выбор генератора для обоих писем. При такой реализации все что необходимо хранить в БД - это номер генератора, который должен быть одинаков для 2 писем.
На этом я закончу мой рассказ про систему рассылок. Мне кажется, что я рассказал про наиболее важные и интересные моменты. Если какие-то моменты остались забытыми, то всегда есть возможность для дискуссиию.